How we solved the LaTeX caching problem that never ended
THE CONTEXT
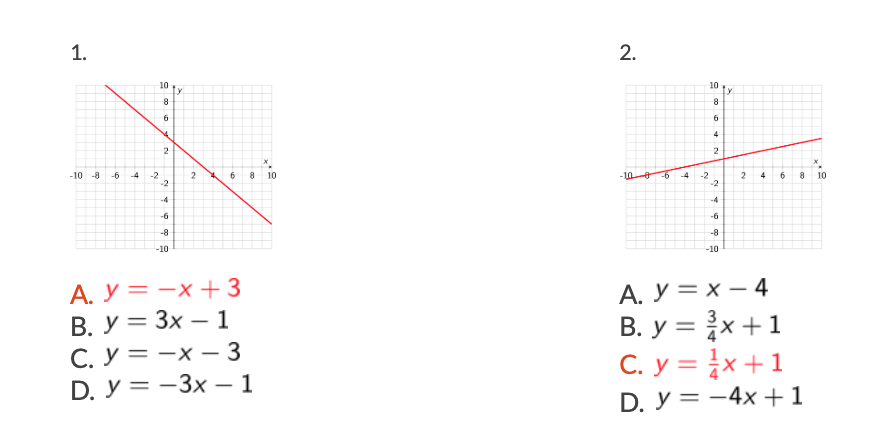
For one of our clients, we built and now maintain software that allows teachers to create math worksheets for their students. Many of these worksheet questions have students select the equation that matches a provided graph, choosing from four different options (labeled A, B, C and D).
To get the math symbols to display properly, we use the LaTeX library, and save the equation display as an image. Since that means every worksheet page loads a dozen-plus images, we locally cache the equation images on-demand on the server the first time a worksheet is loaded. This means every time you subsequently load that worksheet, it's fully cached and loads instantly, which is great!
To do this, we took the literal LaTeX string (a hex digest) used to represent the equation and cached that string. That string was also used to create the filename for the image of the equation, which we'd then look up to load the proper image.
Sounds great, right?
THE PROBLEM
Recently, it came to our attention that the caching wasn't working as expected.
The client would make a new worksheet with new questions, and after visiting the completed worksheet once, expected it to be cached, and therefore load instantly the next time he loaded the page.
Instead, it was still loading each of the graphs individually every time he refreshed, indicating that caching was broken.
But was it?
After some deep investigating, we discovered that, in fact, caching was working, but we'd made some assumptions during the MVP building phase that were no longer holding up now that so many folks were using the software.
To make it harder for students to game the system, answers to questions on the worksheet appear in randomized order. We then cache each answer on page load, including the label (A, B, C or D).
Randomization to the (not) rescue
Which seems reasonable enough - except this means in practice that, because of the randomization, the first n number of page loads were viewed by the code as a new configuration not yet cached (because now the equations associated with question 1, for example, each had a different label, and had to be cached with that specific label).
We were ignoring the cached answers if the expected equation wasn’t paired with the expected letter, which - because of the randomization - was most of the time.
Additionally, sometimes the same equation would be displayed in a slightly different way or place, thus tweaking the hex digest, thus meaning the image didn’t get cached. For example, if you were looking at the answer key for the worksheet, the correct equation choice for each question would appear in red. This means that - even though the equation itself is the same - the LaTeX string representing it is slightly different, and so it wasn't being cached when the original was created ... because technically, it was a different image.
THE SOLUTION
We made three major changes to our caching system to fix this issue.
Getting rid of those pesky labels
This was pretty simple - we just stopped caching the label portion of the answers, because the label load time is infinitesimal. Instead, we only cache the image of the equation, which means it's now cached anytime that equation is displayed (no matter what spot it occupies in the list of possible answers).
S3 vs. local server
Instead of caching on the local server, we now store our cache on S3. This not only improves performance, but also storage maintenance. It's a lot easier to have S3 render the images than the server.
Innate caching instead of on-demand caching
It was clear that caching on-demand wasn't sufficient anymore, so we wrote a script to find all the variations of already cached images, cached them, and put them on S3.
Additionally, we wrote a hook to do same thing every time new questions or answers are created or edited, instead of waiting for that question or answer to be viewed first.
TAKEAWAYS
First, the hex digest naming system is powerful, but only when used correctly (and carefully!).
Second - as every programmer knows - caching is hard.
Thirdly, it's important for startups to actively plan for future development above and beyond the MVP (minimum viable product).
From a business perspective, it just makes sense to ignore a variety of edge cases at the very beginning. But if the product or service becomes successful, then it's equally important to re-evaluate those edge cases (and actively look for new ones!) as more and more users engage with the software.